
测试背景 #
本次测试在本地,用3个库做同步测试,由canal_master_1和canal_master_2往canal_sync同步数据
文件配置 #
canal的配置会涉及到文件夹、配置文件、配置文件之间的关联,总的逻辑关系如下
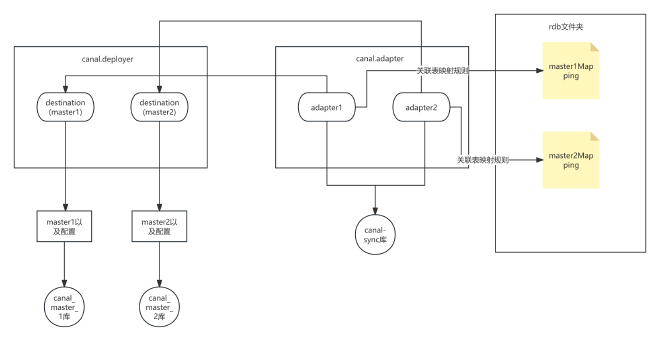
deployer配置 #
deployer的主要作用是对数据库进行监听,伪装destination的从库,解析其binlog
canal/conf/canal.properties 是deployer主配置我们主要关注destinations下的配置
#################################################
######### destinations #############
#################################################
# master1和master2对应着conf下的两个文件夹,其中存放着具体的监听库信息、库表过滤规则等
canal.destinations = master1,master2
ps:多余配置已经裁剪,只关注主要修改配置
master1(2)文件夹配置 #
master1(2)文件夹就对应着destinations中的配置项,其含义是被监听的数据源,该文件夹下存放其相关配置在instance.properties
# username/password
canal.instance.master.address=127.0.0.1:3306
canal.instance.dbUsername=root
canal.instance.dbPassword=12345678
canal.instance.connectionCharset = UTF-8
# 默认监听源数据库
canal.instance.defaultDatabaseName=canal_master_1
canal.instance.enableDruid=false
# table regex
canal.instance.filter.regex=canal_master_1.order,canal_master_1.order_item
adapter配置 #
adapter端的作用是解析来自deployer端的binlog数据并适配转储到各种数据库本次案例中是从mysql适配到mysql.
adapter的主配置在conf/application.yml
outerAdapters代表着外部适配器配置,也就是conf配置下单独拎出来文件夹存放配置的意思
- name 代表文件夹名称,这里mysql使用的是rdb
- key 是代表具体配置名称,该配置主要是配置映射规则
- properties 其下配置的是需要同步到的数据库,及目标库这里目标库只有一个canal_sync所以保持一致即可
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
flatMessage: true
zookeeperHosts:
syncBatchSize: 1000
retries: -1
timeout:
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
canal.tcp.server.host: 127.0.0.1:11111
canal.tcp.batch.size: 500
srcDataSources:
defaultDS:
url: jdbc:mysql://127.0.0.1:3306/canal_master_1
username: root
password: 12345678
canalAdapters:
- instance: master1 # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: rdb
key: master1Mapping
properties:
jdbc.driverClassName: com.mysql.jdbc.Driver
jdbc.url: jdbc:mysql://127.0.0.1:3306/canal_sync
jdbc.username: root
jdbc.password: 12345678
druid.stat.enable: false
druid.stat.slowSqlMillis: 1000
- instance: master2 # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: rdb
key: master2Mapping
properties:
jdbc.driverClassName: com.mysql.jdbc.Driver
jdbc.url: jdbc:mysql://127.0.0.1:3306/canal_sync
jdbc.username: root
jdbc.password: 12345678
druid.stat.enable: false
druid.stat.slowSqlMillis: 1000
outerAdapters #
配置master1Mapping.yml时可以用dataSourceKey 关联数据源,也可以使用destination来关联数据源
#dataSourceKey: defaultDS
destination: master1
groupId: g1
outerAdapterKey: master1Mapping
concurrent: true
dbMapping:
database: canal_master_1
table: order
targetTable: order
targetPk:
id: id
tenant_id: tenant_id
mapAll: true
commitBatch: 3000 # 批量提交的大小
至此配置已经完成,接下来我将针对给出的配置给到具体的测试数据
测试报告 #
双库插入,同步库同步情况 #
测试案例: master1 和 master2 各自写入一条数据观察 canal_sync库数据情况
测试结果:
我们可以通过日志观测到数据已经被adapter解析并执行同步

验证destination 和 dataSourceKey #
-
测试案例: 注释掉master1Mapping 和 master2Mapping 中的destination,启动后做数据同步
测试结果: 数据同步均失败
-
原因分析: 默认情况下adapter会从deployer中拉取binlog,并转换成目标格式。但是在某些情况下可能需要进行回查等操作,就需要用到 dataSourceKey中的配置信息
至此此次测试案例结束
参考链接: srcDataSources的作用是什么